
東京財団政策研究所「リアルタイムデータ等研究会」メンバー
東北学院大学経済学部准教授
1. 「ビッグデータ時代」の到来
近年は、消費者の購買行動や巷のトレンドを調べるために、いわゆる「ビッグデータ」と呼ばれる多種多様かつ大量の情報を使った分析が盛んに行われている。例えば、コンビニエンス・ストアの POS (Point of Sales) データやソーシャル・メディアの投稿情報からトレンドや関連性を統計的に抽出し、その情報を源泉として商品開発やプロジェクトの策定に活用するものである。POSデータであれば、ある商品がいつ・どれだか売れたのかなどが記録されており、データ量としては膨大なものになる。これまでは取り扱うことの出来なかったデータ量は、計算端末の機能向上により、分析処理が可能となった。これにより、「量が質を凌駕する」という言葉に代表されるように、統計を活用した大規模データの分析が時代の潮流として、多方面で賑わいを見せている。
大規模データを利用した実証分析は、経済分析でも普及し始めている。先に紹介したPOSデータは、消費者の購買行動すなわちミクロ経済学の個人行動を示す有力な情報源であり、マーケティングを中心に盛んに研究されている。また、計量ファイナンス分析においても高頻度データだけでなく大規模データへの実証が進められている。例えば、日本取引所グループに上場する株式でポートフォリオを考える場合では、約3600 種類の銘柄から選択することになる。
そして、本稿が取り組むマクロ経済分析でも、工業統計であれば産業別や財別に集計されているほか、物価であれば財別にあり、大規模データ利用のための情報リソースは潤沢に存在する。例えば、Iiboshi et al., (2015) では利用可能情報が潤沢にある環境を「Data rich」と呼称し、多種の経済統計を用いて、動学的確率一般均衡モデルと呼ばれるマクロモデルの推定を行っている。今後はこうした大規模データ利用の有用性が様々な経済分析に検証されていくものとみられる。本稿では、景気分析に焦点を当て、この大規模データ利用が景気後退や拡張などの景気判断に対してどれほど有用であるのかについて検証していきたい。
2. 景気分析における大規模データ利用の利点・欠点
ここでは、まず、大規模データを用いて景気分析する際の利点と欠点について考える。大規模データを利用することで、対象たる経済状況に関するデータ量が飛躍的に上昇することが大きな利点であろう。その他には、これまで日本の景気をデータから抽出するにあたって必要であったデータ選択における試行錯誤の必要性がなくなることがある。
大規模データの利用には欠点もある。第1に、データ選択における試行錯誤の必要性がないということは、何が景気を測る上で重要であるかというロジックを捨てることと同義となる。これにより、例えば、働き方改革などの政策と景気との関係性を測ることが出来なくなる。第2に、景気そのものが大まかな概念でしかなく、購買行動など結果が明確なものとは異なることから、どれだけデータを揃えれば良いのかという問題もある。最後に、データ管理の問題がある。経済統計には、実質値や指数のような加工統計が数多く存在している。これらの統計には基準改定が定期的に行われる。観測点のデータ(例えば交通量の観測データ)であれば、日々の状況をストックし続ければ良い。しかし、上記のような経済統計は定期的に入れ替えが必要となるため、データが多くなるほど管理が大変になる。このように景気分析では、大規模データの利用は恩恵もあるが多くの問題点も含んでいる。
3. 先行研究と本稿のアプローチ
大規模データを用いた景気分析に関連する先行研究と本稿のアプローチについて紹介する。大規模データを用いた景気分析は、幾つかの方法によって応用がなされてきた。具体的には、近似ファクターモデル (Stock and Watson, 2002)、周波数分析 (Forni et al., 2005)、状態空間モデル (Kapetanious and Marcellino, 2009) が挙げられる。ただし、国内での大規模データによる実証分析は、飯星 (2007) と早川・小林 (2011) のみであり、研究結果の蓄積は多くない。
本稿では、大規模データ利用の有用性を考察するために、最もシンプルかつ計算負荷の低い近似ファクターモデルのアプローチによって分析を進めていく。近似ファクターモデルによる今回の分析においては、主成分分析により、用いるデータの固有値と固有ベクトルから共通因子をまず抽出する。次に、抽出された共通因子を所与として、Ohtsuka (2018) で用いられている景気の構造式を推定し景気後退確率を推計する。共通因子を所与とすることで、景気循環や変動リスクの推定は、1変量の推定に次元縮小できることから、計算負荷を大きく減らすことが可能である。
4. 景気後退確率の推計
ここでは、具体的な分析結果を示す前に、まず、どれだけのデータを利用するかについて説明する。先行研究をみてみると、飯星 (2007) では126系列、早川・小林 (2011) では163系列のデータが用いられており、100 種類以上のデータによる分析が大規模データの実証分析に該当すると考えられる。本稿では、工業生産70系列、物価17系列、雇用15系列、金融5系列、販売4系列、その他4系列で合計115系列を用いる。詳しいデータについては付表を参照されたい。サンプル期間は2000年1月から2019年4月までの月次の値を用いる。
大規模データを用いた結果の有用性を調べるために、分析に当たっては、以下の2つの結果を比較対象とする。1つ目が、第9回の本稿でも紹介した8系列による小規模データ (以下、CI8と略称する) を用いた結果である。具体的には、鉱工業生産指数、鉱工業用生産財出荷指数、耐久消費財出荷指数、所定外労働時間指数、投資財出荷指数、消費総合指数、第3次活動指数、企業物価指数 (需要段階別素原材料) の8系列である。もう1つが、内閣府が公表する外れ値調整無しの景気動向指数 (Composite index: CI) を共通因子として用いた結果である。
(分析結果①:共通因子の動き)
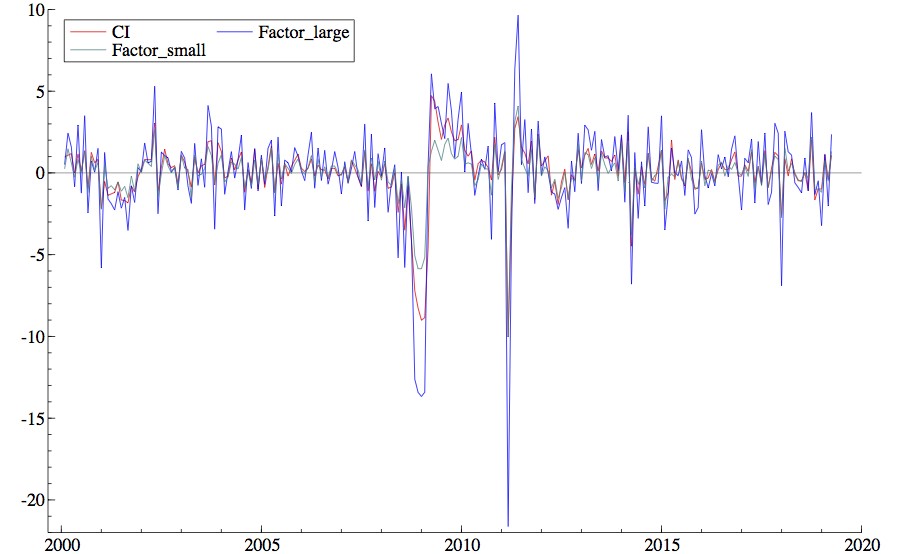
図1は、大規模データを用いて求めた共通因子 (Factor large)、CI8を用いて求めた共通因子 (Factor small) と CI の変化率を比較したものである。大規模と小規模のデータセットによって抽出された共通因子は、振れ幅に違いはあれども、いずれも概ねCIと同様の変動になっていることがわかる。
図1 共通因子の抽出結果
(分析結果②:大規模データを用いた景気後退確率)
次に、大規模データによる景気判断を示すものとして、景気後退確率の推移に着目する。図2の実線は、大規模データを用いた推計結果を示したものである。図2より、景気後退確率が50%を超える局面が数多く見られる。図2の影の部分は景気後退確率が8カ月以上50%を超える期間を景気後退期としてピックアップして示したものである。公的な景気後退期の判断は、6カ月以上の景気後退が続いた場合とされるが、実際に公表された景気後退期で最も短い期間は、第15循環の8カ月であることから8カ月以上とした。
図 2 大規模データを用いた景気後退確率
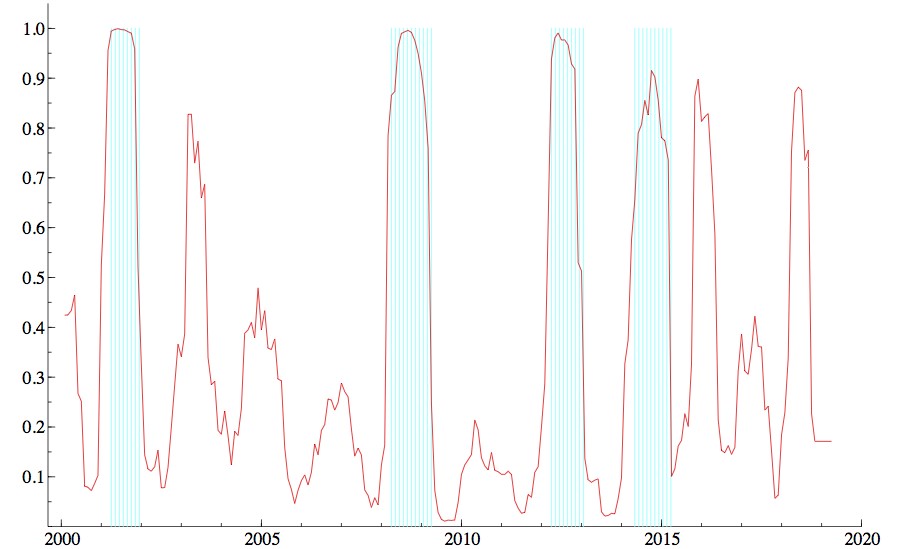
(注)影の部分は、大規模データを用いて求めた景気後退期を指す。景気後退確率が8か月以上50%を上回る期間をピックアップしている。
ここで、どれほどの精度で景気循環を捉えられているかを詳細にみるために、内閣府経済社会総合研究所 (Economic and Social Research Institute: ESRI) によって公表された景気の転換点と比較してみる。表1は、ESRIの公表値と大規模データの結果についてまとめたものである。大規模データによる景気の転換点は、これまでと同様に景気後退確率が8か月以上50%を上回るかどうかで考えている。ESRIの転換点と比較すると、大規模データによって推計される転換点の誤差は±2カ月以内となっていることから、一定の精度があると考えられる。しかし、ESRIの公表値にはない2014年 3月から2015年3月までの12カ月間を景気後退期と判断している。この期間については、消費税率が5%から8%に引き上げられた時期であり、こうした税負担の増加が景気の減退を引き起こしたのかもしれない。
表1 景気の転換点の比較

(注)日付は月/年を表す。誤差は、例えば、-1であれば大規模データがESRIに比べて1カ月早いことを示す。
(分析結果③:景気後退確率の比較)
最後に、景気後退確率の比較を行う。図3は、結果毎の景気後退確率(実線)とESRIが公表する景気後退期(影の部分)を描いたものである。
図3 景気後退確率の比較
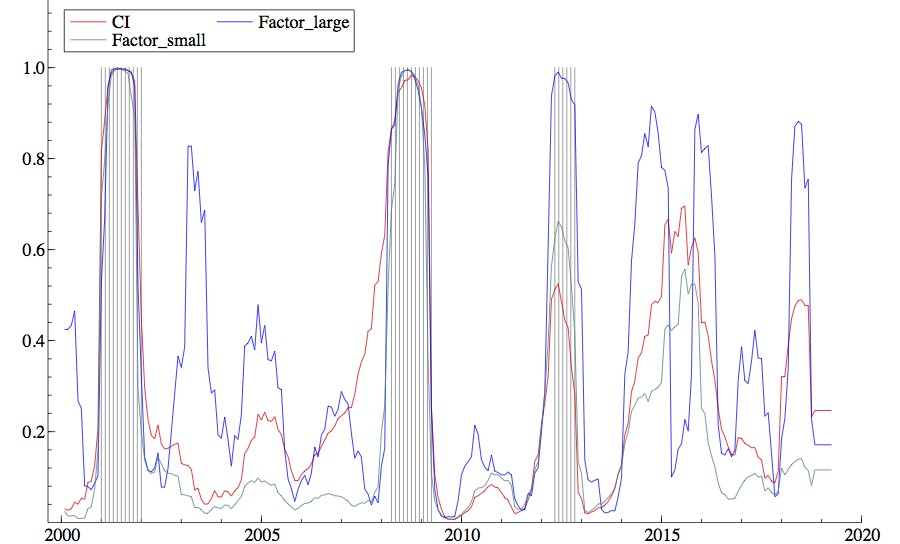
(注)影の部分は、ESRI公表の景気後退期を指す。
図3より、全ての結果においてデータ期間中の公的な景気後退期を概ね捉えているといえる。しかし、大規模データを用いた推計結果は、後退確率が50%を超える回数が他の結果よりも非常に多いことから、先述したように50%を超える後退確率が6~8カ月以上続くなどの条件を課すなどして、判断した方が良いことがわかる。また、2014年4月から2016年5月までの期間に注目すると、大規模データを用いた結果が多峰型になっているのに対して、CI8とCIを用いた景気後退確率は大規模データを用いた結果の形状を平滑化したような状態になっている。この点は、どの個別データが影響を及ぼしているのかを明らかにしていかなければならない。
5. まとめ
本稿では、100種類以上の経済統計を用いる大規模データセットを利用した景気後退確率の推計を行った。推計結果より、ESRIの公表する景気基準日付はうまく捉えられていることが示された。しかし、データ量が多すぎることで過剰に景気後退を抽出している可能性は否めない。これによりリアルタイムデータなどで運用する際には、確率の持続期間など判断基準を設ける必要がある。この点については、検証と調整を積み重ねていく必要があろう。
さらに、今後は、景気の現状を表す一致指標だけでなく、景気に先行する経済指標の探索や、景況感などのセンチメントによる指標作成も必要であろう。例えば、現在、あまり改定がなされていない景気動向指数の先行指数の予測精度や、数ヶ月先の状況について回答するサーベイデータと景気の関係性などについて検証することを今後の課題としていきたい。
付表 データ一覧

参考文献
Forni, M., Hallin, M., Lippi, M. and L, Reichlin (2005), “The Generalized Dynamic Factor Model: One-Sided Estimation and Forecasting,” Journal of the American Statistical Association, 100, pp.830–840.
早川和彦・小林庸平 (2011) 「大規模マクロデータを用いた景気動向分析」『ファイナンス・景気循環の計量分析』(浅子和美・渡部敏明 編),91–112 頁
飯星 博邦 (2009) 「主成分分析によるマクロ経済パネルデータの共通ファクターの抽出とその利用」ESRI Discussion Paper Series, No.219.
Iiboshi, H., Matsumae, T., Namba, R. and S, Nishiyama (2015) “Estimating a DSGE Model for Japan in a Data-Rich Environment,” Journal of Japanese and International Economies, 36, pp.25–55.
Kapetanios, G. and M. Marcellino (2009), “A Parametric Estimation Method for Dynamic Factor Models of Large Dimensions,” Journal of Time Series Analysis, 30, pp.208–238.
Ohtsuka, Y. (2018), “Large Shocks and the Business Cycle: The Effect of Outlier Adjustments,” Journal of Business Cycle Research, 14, pp.143–178.
Stock, J. H. and M. W. Watson (2002), “Forecasting using principal components from a large number of predictors,” Journal of American Statistical Association, 97, pp.1167–1179.
 大塚 芳宏 東北学院大学経済学部准教授
大塚 芳宏 東北学院大学経済学部准教授
1979年東京都生まれ。2006年千葉大学修士(経済学)、金融機関の営業・調査部に勤務。2012年一橋大学経済学研究科で博士号取得後、北海道大学大学院経済学研究院助教、長崎県立大学経済学部講師を経て、2015年から現職。
関連記事
-
-

- 元 主席研究員
- 大塚 芳宏
- 大塚 芳宏
- 研究分野・主な関心領域
-
- 景気循環分析
- ベイズ計量経済学
- 時空間計量経済学
-

注目コンテンツ
-
【論考】誰のための副首都構想なのか、見極めが必要だ
【論考】誰のための副首都構想なのか、見極めが必要だ
-
【論考】在留資格「技人国」をめぐるトラブルは何を示しているのか―賃金未払い・突然の解雇から考える雇用責任と在留リスク
【論考】在留資格「技人国」をめぐるトラブルは何を示しているのか―賃金未払い・突然の解雇から考える雇用責任と在留リスク
-
【論考】在留資格「技人国」による雇用実態はなぜ見えにくいのか―統計と現場のあいだ
【論考】在留資格「技人国」による雇用実態はなぜ見えにくいのか―統計と現場のあいだ
-
【論考】防災情報をより多くの住民へ届けるために 静岡県「わたしの避難計画」と企業・地域メディアの連携
【論考】防災情報をより多くの住民へ届けるために 静岡県「わたしの避難計画」と企業・地域メディアの連携
-
日本のポピュリズム2.0
日本のポピュリズム2.0














































